Workflow
- By Arize Skills
- By Alyx
- By UI
- By Code
Coming soon!
Load or generate data
Open Alyx and load your data, or ask it to generate examples from your use case. You can also start from a production span—Alyx has the full context automatically.
Load your prompt
Ask Alyx to load a prompt from Prompt Hub. For dataset runs, make sure to align
`{variables}` referenced in your prompt with dataset columns.Create an evaluator
Ask Alyx to draft an evaluator. Describe what you want to evaluate and it sets up the labels and criteria.
Review results
Open Datasets & Experiments to compare outputs, latency, tokens, and scores from evaluators. You can also ask Alyx to summarize the results for you.

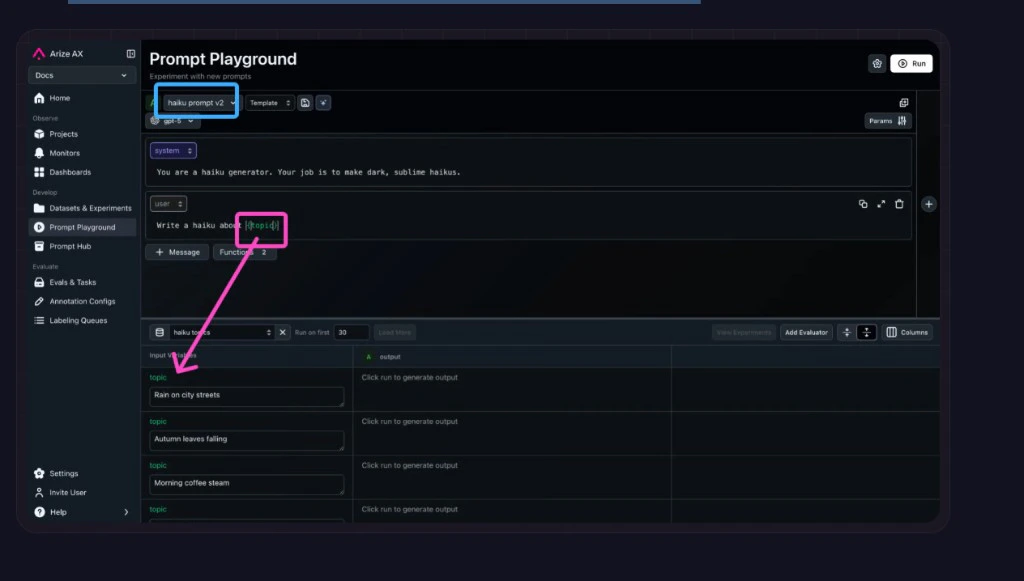
On a dataset
When modifying a prompt in the Playground, you can test your new prompt across a dataset of examples to validate that the model is hill climbing in terms of performance across challenging examples, without regressing on core business use cases.Create a dataset
Follow Build a dataset to upload your dataset to Arize AX.
Select your dataset in the Playground
Go back to the Prompt Playground and choose your dataset from the Select a Dataset dropdown.
Load or write your prompt
Load a prompt from Prompt Hub using the Select a template from Prompt Hub dropdown. Or fill in a new prompt (see Build a prompt). Include variables from your dataset in the prompt inside curly braces (for example
`{destination}`).Attach evaluators
Evaluators score each row. Attach an evaluator: code-based for deterministic checks, or LLM-as-a-Judge for qualitative scoring.
Run and review
Click Run. The Playground fills each row’s variables, calls your model, and scores the output. Open View Experiment to compare results and look for patterns. For each row, the Playground substitutes values into the template, calls your model, and runs every attached evaluator on the generated output.
On a span (replay)
Load any production span directly into the Prompt Playground. All parameters, messages, variables, and function definitions are auto-populated so you can iterate on the exact call that went wrong. See production replay for the full walkthrough.Span replay bridges production traces and prompt iteration: you get the real execution context instead of guessing what caused a response—the same inputs, variables, and function calls you saw in production, ready to experiment on.With span replay, you can:- Debug in context — Reproduce the precise LLM invocation that occurred in production, including all inputs and configurations.
- Iterate instantly — Adjust prompts, parameters, or models and re-run them on the same real data, no manual reconstruction needed.
- Validate improvements — Compare responses side by side and ensure changes lead to measurable quality gains.
- Accelerate experimentation — Turn traces into actionable testing environments for faster, data-driven prompt refinement.

Multiple prompts at once
Compare up to three prompts side by side against the same dataset and evaluators. Use the + button to add prompt objects. See compare prompts side by side.With tool calls
Tools drive agentic workflows, but debugging them is fiddly: unclear descriptions or parameter specs, wrong argument values, the LLM skipping or mis-picking a tool, or a missing tool for the user input.The Prompt Playground can pull tools from span data automatically (easiest when function calls are traced), so you iterate on prompts in the same tool setup you saw in production. Open Functions to edit or add tool definitions as JSON (use a list of objects for multiple tools) and configure Function Selection so the model gets clearer instructions on when to invoke each tool.See using tools in the Playground.With image inputs
Multimodal models such asgpt-4o accept image URLs as variables. Add an `{image}` variable to your prompt, paste a URL into Input Variables, and run. Supported formats: JPG, PNG, GIF, SVG, WebP. Supported URL types: https://, gs://, s3://, base64. See image inputs in the Playground.


To run the same kind of checks in code - over every dataset row, with scores from evaluators logged and compared in Datasets & Experiments - use the Experiments docs:
- Set up an experiment - overview of datasets, runs, and comparisons
- Run an experiment - execute a task against a dataset
- Log experiment results - record outputs and metrics